March 30, 2023
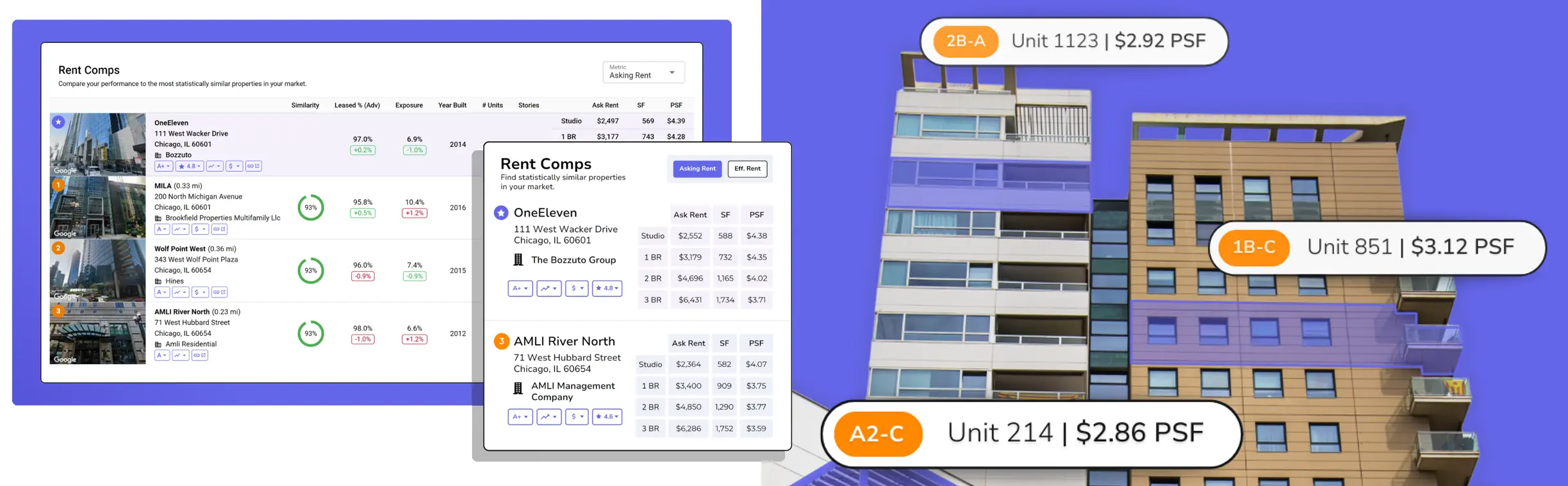
Rent Comps: How to Identify Comparable Properties at Scale
Quality Score can be used to assess the interior and exterior quality of listings at scale, making the scalable detection of comps feasible.
.svg)

Most real estate companies generate a ton of data through listings, purchase & sale agreements, market studies, site inspections, etc… the list goes on. Large volumes of data can be very powerful for analysis, but in real estate, this data tends to be locked in emails, PDF documents, and Excel models. It’s essentially unusable, unless the data can be extracted in a consistent way. With recent advancements in artificial intelligence (AI), however, it is becoming significantly easier for real estate companies to unlock the value of their data.
In this article, we’ll cover how data extraction algorithms work, why they are important for real estate workflows, and how to get started automating data extraction for your business.
Data extraction software typically utilizes a combination of Optical Character Recognition (OCR) and either Machine Learning (ML) or conditional logic to extract structured data from a variety of documents. Here are a few different approaches we’ve seen in the market and used in our own data extraction projects, as well as a summary of where each is useful:
If you have documents with a consistent format, with maybe a few dozen document variations, this approach can produce great results. It involves converting scanned documents to readable text, then applying conditional logic to determine which type of template it is and how to treat the data.
This approach works well for documents like rent rolls or certificates of insurance. The formats may vary significantly across documents, but there are a finite number of variations that can be all accounted for (with some effort). The data points that need to be extracted are also referred to in a consistent way across documents and located in similar locations within each document. It may be very labor-intensive to cover every document variation, but the outputs will be very reliable with this approach.
With this approach, an ML model is trained to “understand” the structure of the data and the relationships between data points. Instead of simply extracting text, it can identify specific data points and assign them appropriate labels. This approach can cover a much wider array of document types, with a greater number of variations across documents.
It works well for many different document types, but it has some drawbacks. For example, it could require substantial categorization and labeling work to cover a new document type. We’ve heard of providers that need thousands of documents to train new models, and a human on the clients’ side to continually check outputs until the results are reliable enough.
In addition, for complex cases like commercial leases, these models won’t understand the meaning of clauses and how they relate to each other. For example, a Right of First Refusal (ROFR) clause might be detected, but the fact that it is subordinated to three other ROFR clauses (rendering it essentially meaningless) probably wouldn’t be. So you may end up with extracted data that looks correct, but is inaccurate in the broader context of the document.
We use OCR coupled with machine learning to extract data in tables and simple documents, but we developed a unique approach that can deliver highly accurate results with only 20-30 training documents. Additionally, we handle all of the training and edge case detection for clients, so adding support for new document types is significantly easier with AnyExtract.ai.
This approach leverages the latest advancements in LLMs like OpenAI to understand the meaning of an entire document. With these models, the relationships between different parts of a document can be understood by the algorithm, and complex terms can be accurately accounted for.
For example, in a commercial lease, using an LLM to extract “renewal option terms” could produce outputs such as "One 5-year option at market rent", "Two 5-year options at 2% above current rent", or "No renewal option". These specific words don’t need to appear in the text like they do in the other approaches… the LLM can understand that a full paragraph describing renewal terms should be summarized as “Two 5-year options at 2% above current rent" and return that as an output. This is the closest thing to having an attorney review and summarize your document – like an automated lease abstract.
The potential drawbacks we’ve seen with this approach are false positives and “imagined values” that are not actually anywhere in the document. In one instance, since the tenant name wasn’t filled in on a residential lease, the LLM we used produced a value of “John Doe” for the tenant. If you prompt an LLM with something that doesn’t make sense, you’ll still get an answer – but it might be nonsense. Garbage In, Garbage Out, as they say. That’s why it’s critical to spend time on prompt engineering and testing to get consistent results. Once you do, though, we believe this approach is the most powerful of the three.
A consistent approach to data extraction builds a strong foundation for data analysis by combining and structuring data from internal and external systems. Here are a few benefits of using automated extraction systems like AnyExtract.ai:
Automation can help quickly access unstructured data sources that would be difficult to find manually. If every time you need a piece of information, you have to find the document in your file management system, then find the portion of the document with the answer you need with Ctrl + F… that really adds up. Automated data extraction puts the data you need at your fingertips, reducing delays and accelerating decisions.
Manual data extraction is expensive due to the numerous checks required and staffing needs. We’ve heard of real estate companies spending millions a year for overseas document processing, or having a team of internal people whose only job is to transcribe data from PDFs to Excel workbooks. Automatically extracting data from common document types can help reduce costs and get results faster.
As experienced as they may be, human beings make mistakes (particularly when they are processing the same document types all day). Automating the extraction process can significantly reduce data entry errors, such as incomplete records, missing items, and duplicate values.
Real estate is a highly competitive industry, but the majority of the industry is still spending inordinate amounts of time manually moving data from one document type to another. Automating real estate data extraction is becoming essential to save time and money, but it’s even more critical to improve retention and limit burnout across your team.
AnyExtract.ai is the easiest real estate data extraction product to get started with. To try it out, just send your commercial lease to data@hellodata.ai with “Commercial Lease” in the subject line, and our algorithm will extract the key terms and send a summary back to you in minutes.
If you want to learn more about our bulk discounts or discuss implementing our algorithm for a particular document type, reach out at contact@hellodata.ai, and we’d be happy to discuss!